Here’s our poster:
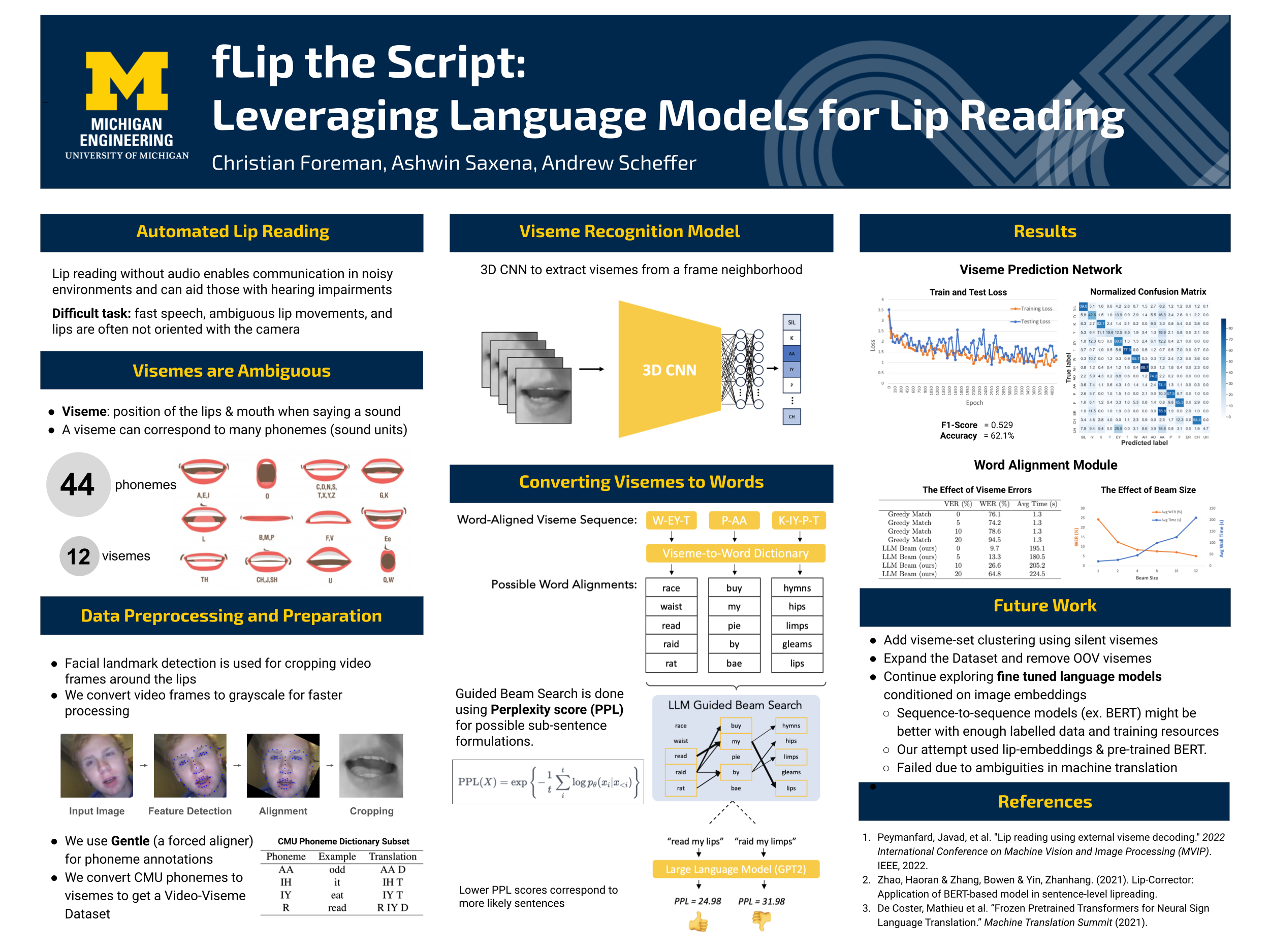
Lip reading is a crucial aspect of communication, especially in noisy environments. This project proposes a novel lip-reading system that utilizes large language models (LLMs) to predict likely spoken sentences by decoding sub-word “viseme” sequences. The system outperforms a greedy decoding scheme and motivates future work incorporating textual priors into lip reading systems.
Methodology
The proposed lip reading system comprises a Viseme Prediction Network (VPN) and a Word Alignment Module (WAM). The VPN identifies visemes using a 3D CNN, trained on a new dataset created by the team. The WAM constructs sentences using a large language model (GPT-2) through guided beam search.
Results
The VPN achieved a 62.1% accuracy and a Macro F1-score of 0.529. The confusion matrix revealed challenges in distinguishing certain viseme classes. Comparative performance between the Greedy Match algorithm and the proposed LLM Beam approach showed superior results for the latter in Word Error Rate across various Viseme Error Rates.
Our overall pipeline is split among two Github Repos and a Python Notebook
- This contains the code for pre-processing video data: https://github.com/schefferac2020/LipReading
- This contains the code for the Viseme Prediction Network: https://github.com/ChristianForeman/VPN
- The notebook for the beam search is here [TODO]